Unlocking Local AI: How NVIDIA and Google's Gemma 4 Brings Agentic Intelligence to Your Device
Open-source AI models are reshaping how we interact with technology, moving intelligence from the cloud directly onto our everyday devices. Google's latest Gemma 4 family represents a leap forward in this shift—compact, fast, and omni-capable models designed for efficient local execution. Through a close collaboration with NVIDIA, these models are optimized to run seamlessly across a diverse hardware ecosystem, from data-center GPUs to personal RTX-powered PCs, the DGX Spark personal AI supercomputer, and even edge modules like the Jetson Orin Nano. This Q&A explores the key aspects of Gemma 4, its capabilities, and how it empowers developers to build powerful, context-aware agentic AI systems that operate entirely on-device.
What is Gemma 4 and why is it important for local AI?
Gemma 4 is Google's newest family of open-weight language models, crafted specifically for on-device deployment. Unlike massive cloud-bound models, Gemma 4 emphasizes efficiency without sacrificing capability—making it ideal for scenarios where low latency, privacy, and offline operation matter. The family includes four variants: E2B, E4B, 26B, and 31B parameters. The E2B and E4B are ultra-lightweight, designed for edge devices like the Jetson Nano, offering near-zero latency inference completely offline. The larger 26B and 31B models target high-performance reasoning and agentic workflows, running efficiently on NVIDIA RTX GPUs and the DGX Spark. By collaborating with NVIDIA, Google ensures these models take full advantage of GPU acceleration, making local AI not just possible but practical across a wide range of hardware—from everyday PCs to dedicated AI supercomputers.

What are the different Gemma 4 model variants and their target devices?
Gemma 4 comes in four distinct sizes, each optimized for a specific deployment scenario. The E2B and E4B models are the smallest, engineered for ultra-efficient, low-latency inference at the edge. They run completely offline on devices such as the NVIDIA Jetson Orin Nano module, making them perfect for embedded systems, robotics, and IoT applications where power and connectivity are limited. The 26B and 31B models are larger and more powerful, tailored for high-performance reasoning and developer-centric tasks like coding assistants and complex agentic workflows. These models run efficiently on NVIDIA RTX GPUs found in PCs and workstations, as well as on the DGX Spark personal AI supercomputer. This spectrum ensures that whether you are building a lightweight voice assistant on a microcontroller or a sophisticated AI agent on a desktop, there is a Gemma 4 model suited to your hardware and performance needs.
What capabilities do Gemma 4 models offer beyond basic language tasks?
Gemma 4 models are not just text generators—they are multimodal and agent-ready right out of the box. Key capabilities include:
- Reasoning: Strong performance on complex problem-solving tasks, enabling logical deduction and multi-step analysis.
- Coding: Native support for code generation and debugging, streamlining developer workflows.
- Agentic Functions: Built-in structured tool use (function calling) for building autonomous agents that can interact with applications and data.
- Vision, Video, and Audio: Enables rich multimodal interactions like object recognition, automated speech recognition, and document or video intelligence.
- Interleaved Multimodal Input: You can mix text and images in any order within a single prompt, allowing flexible queries.
- Multilingual Support: Out-of-the-box support for over 35 languages, with pretraining on more than 140 languages, making them globally accessible.
These features make Gemma 4 a versatile foundation for a wide range of local AI applications, from personal assistants to intelligent automation.
How do Gemma 4 models perform on NVIDIA hardware?
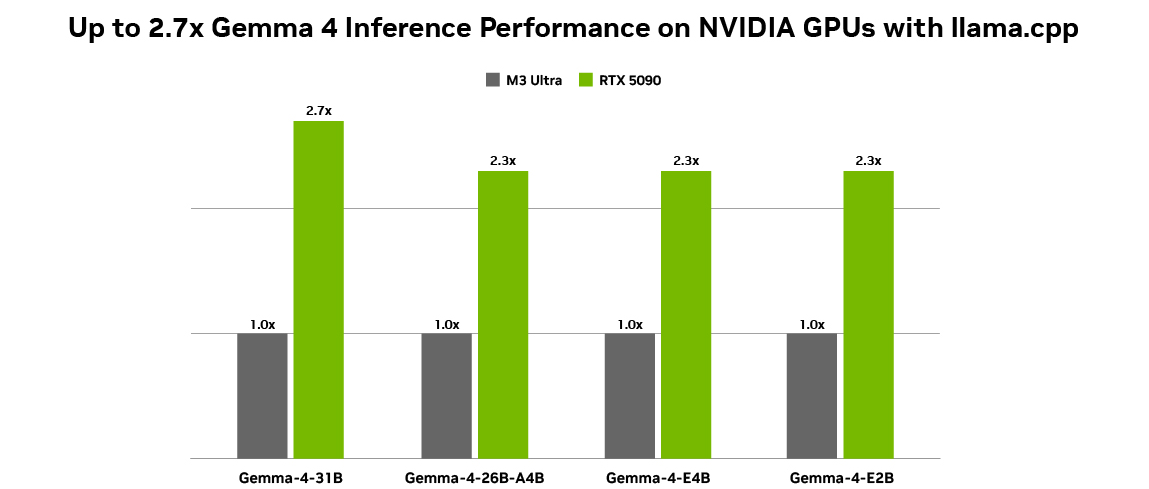
The collaboration between Google and NVIDIA ensures that Gemma 4 models achieve excellent performance across NVIDIA's GPU lineup. For benchmarking, standardized measurements were taken using Q4_K_M quantization with a batch size of 1, an input sequence length of 4096, and an output sequence length of 128. On an NVIDIA GeForce RTX 5090 desktop, token generation throughput was tested using llama.cpp version b7789 and the llama-bench tool. While exact numbers vary by model size, the optimized inference means that even the largest 31B model runs fluidly on high-end RTX GPUs and the DGX Spark. The smaller E2B and E4B models, designed for edge devices, achieve near-zero latency on the Jetson Orin Nano. This optimization ensures that developers can deploy Gemma 4 for real-time, on-device AI without cloud dependencies—ideal for privacy-sensitive or latency-critical applications.
What is OpenClaw and how does it use Gemma 4 for agentic AI?
OpenClaw is an application framework that enables always-on AI assistants on NVIDIA RTX PCs, workstations, and the DGX Spark. It leverages the latest Gemma 4 models to create capable local agents that can draw context from personal files, applications, and workflows to automate tasks. Because Gemma 4 natively supports structured tool use and function calling, OpenClaw can seamlessly integrate with your desktop environment—reading documents, controlling applications, and executing commands. This allows users to build personalized, privacy-preserving AI assistants that run entirely on-device. Developers can get started for free on RTX GPUs and DGX Spark, using the DGX Spark OpenClaw playbook. This combination of Gemma 4's advanced agentic capabilities and OpenClaw's integration framework marks a significant step forward in making local, context-aware AI a practical reality for everyone.
How can developers get started with Gemma 4 on NVIDIA platforms?
Getting started with Gemma 4 on NVIDIA hardware is straightforward, thanks to comprehensive optimization and tool support. Developers can access the models through Google's official repositories and NVIDIA's AI platforms. For PC users, any system with an NVIDIA RTX GPU (including the RTX 5090) can run the 26B and 31B models efficiently using frameworks like llama.cpp. For edge deployment, the NVIDIA Jetson Orin Nano module is ideal for the E2B and E4B variants. The DGX Spark personal AI supercomputer offers a dedicated environment for high-performance local AI. Additionally, NVIDIA provides playbooks and tutorials, such as the DGX Spark OpenClaw playbook, to help developers build agentic applications. For those new to multimodal AI, the Gemma 4 models come with built-in support for vision, audio, and interleaved inputs, so you can experiment right away. Check out the Google DeepMind announcement blog for more details.
Related Articles
- The Accelerating Risk of Feature Bloat: How AI is Reshaping Product Management
- Kubernetes v1.36 Overhauls Resource Management with Major DRA Upgrades
- 7 Key Insights Into Airbnb's Privacy-First Identity Overhaul
- UK Regulators Investigate Microsoft's Business Software Practices Over Antitrust Concerns
- Breaking: 50-Year-Old Software Wisdom Still Rules – ‘The Mythical Man-Month’ Revisited in 2026
- Mastering Swift 6.3: A Comprehensive Guide to New Features and Practical Usage
- How Open Source Data Exposes the Hidden Digital Complexity of Nations
- Beyond Bot Versus Human: Modern Web Protection in an Era of Blurring Identities